
Readiness probes, like liveness probes, are a type of health check in Kubernetes. They determine whether a container is ready to accept traffic. If a container fails a readiness probe, it is removed from the set of pods used to satisfy requests for the service. This helps you ensure that your Kubernetes clusters are only serving traffic from healthy containers.
In a recent post, I explored some of the liveness probes best practices, which are another type of Kubernetes health check. Readiness probes run continuously and verify whether a Docker container is ready to serve requests. When one of your readiness probes returns a failed state, the IP address for the pod is removed from the endpoints of all services by Kubernetes. You can use readiness probes to indicate to Kubernetes that a running container should not receive traffic until additional tasks have been completed, including loading files, warming caches, and establishing network connections. Use the spec.containers.readinessProbe attribute for the pod configuration to configure readiness probes and define how frequently these periodic probes run using the periodSeconds attribute.
You should seriously consider configuring readiness probes in Kubernetes because they can help you ensure that your applications are only serving traffic when they are healthy. The readiness probes enable you to determine whether a container is ready to accept traffic and remove it from the set of pods that are used to satisfy requests for the service if it is not.
There are a few reasons you should make sure that you configure readiness probes in Kubernetes, including:
Reduced load: If an unhealthy container is serving traffic, it may use resources (CPU, memory, or storage) that other containers need to run reliably, or even exhaust a node's resources, causing a larger system failure.
Improved reliability: When unhealthy containers are running, users may not be able to connect to them, which can result in client facing errors and application outages.
Simplified troubleshooting: If a service is not performing as you expect, you can look at the readiness probes for the containers in the service to see if any of them are failing, which can help you to identify the cause of the problem.
For all these reasons, readiness probes are a useful health check for your Kubernetes cluster. These probes are part of the default checks that Polaris, a Fairwinds open source policy engine for Kubernetes, runs through to help you identify and resolve potential Kubernetes reliability issues. Polaris is also built into Fairwinds Insights, as well as other open source tools, to apply across multiple clusters and maintain consistency across your organization. Polaris can help you improve the health of your Kubernetes clusters by identifying missing readiness probes and creating Action Items in the dashboard. This helps you to quickly see when a readiness probe should be configured and how severe the issue is for your cluster’s reliability.
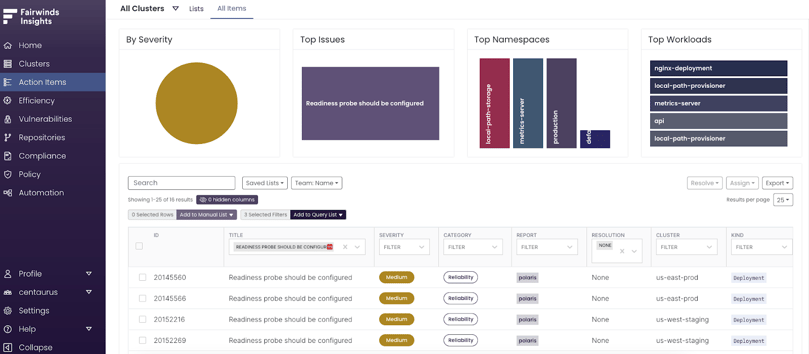
When viewing readiness probes in Fairwinds Insights, pick one of the Action Items displayed when you filter on “Readiness probe should be configured” and click on it to see more details. Those details include when the issue was first seen, last reported time, the namespace, and a detailed description. Review the links to references for relevant documentation and note the high-level steps to remediate the problem, and examples of a remediation to help resolve the issue as quickly as possible.
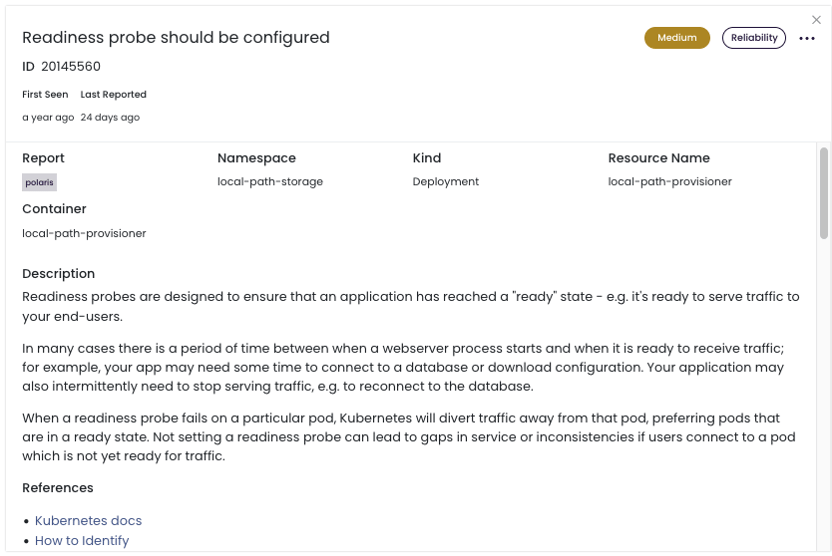
To get more details and live links that describe how to add a readiness probe, use Fairwinds Insights. Use the Insights free tier to find out whether you have any workloads that are missing readiness probes for environments up to 20 nodes, two clusters, and one repo.
I created a short video to walk through the process of configuring a readiness probe. In the example, you can see there is a cluster with a workload and Insights flagged the “Readiness Probe should be configured” Action Item for a specific workload. We add a simple HTTP check to let the kubelet know when the application is ready to receive traffic by modifying the manifest live in the cluster.
```
apiVersion: v1
kind: Pod
metadata:
labels:
insights: readiness
name: readiness-http
spec:
containers:
- name: readiness
image: busybox
args:
- /server
readinessProbe:
httpGet:
path: /healthz
port: 8080
httpHeaders:
initialDelaySeconds: 3
periodSeconds: 3
```In this instance, a simple httpGet is sufficient for kubelet to evaluate the status of the application. Once we restart the deployment with the new readiness probe configured, the Action Item is resolved in Fairwinds Insights and we can be assured that we have increased the reliability of this Kubernetes workload.
Watch the video to walk through resolving the Action Item: Readiness probes should be configured step by step.


