
Kubernetes, the open source platform for managing containerized workloads, provides you with a framework for automating software deployment, scaling, and management. Let’s dig into the scaling part of that — K8s supports three different types of autoscaling: Horizontal Pod Autoscaler (HPA), Vertical Pod Autoscaler (VPA), and Cluster Autoscaler. Figuring out how to make scaling work well for you can be challenging, and understanding how HPA and VPA work together (or don’t) can be confusing. At a basic level:
HPA scales the number of replicas of an application
VPA scales the resource requests of a container
Cluster Autoscaler adjusts the number of nodes of a cluster
We created Goldilocks, an open source Kubernetes controller, to provide users with recommendations on how to set your resource requests in an easy-to-understand dashboard format. Goldilocks uses the VPA controller‘s recommendation engine to generate those recommendations.
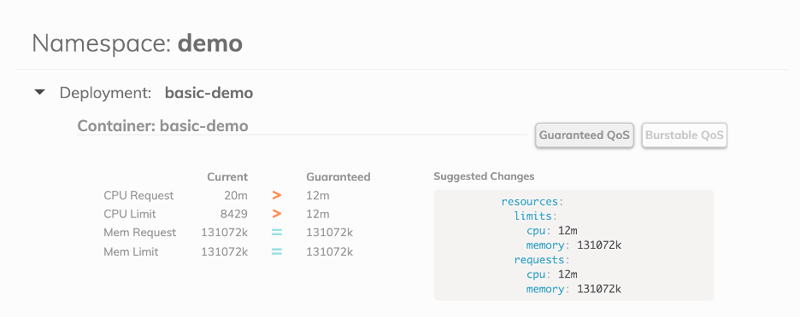
The HPA and VPA act on the same underlying controllers but they treat the problem of resource contention differently. Let's take the example of using CPU utilization as the metric for your HPA and VPA. The HPA is horizontal — when the average CPU utilization across a specified number of pods gets to the percentage you specify, it will spin up a new pod to resolve the issue.
The VPA, on the other hand, changes the request on the pod itself if you get to the specified percentage CPU utilization. So it scales vertically — it references the spec that says what the pod needs and gives it that much more, making the pod itself bigger instead of making more pods.
The challenge is that people often want to use both HPA and VPA to make changes. That can create a problem. Essentially, if you say that you want your pod to get bigger and create more pods based on the percentage of CPU utilization, the VPA uses the information the HPA is set to as its recommendation. That makes the recommendation from the VPA less accurate. So, let’s look at a question about this issue that came into our Slack Community from a Goldilocks user.
It is best if the VPA's updater component is disabled. That's due to the way HPA works; it’s not specific to Goldilocks. We disable the updater component by default if you use our chart:
vpa:
# vpa.enabled -- If true, the vpa will be installed as a sub-chart
enabled: false
updater:
enabled: falseIt’s also important to note that if your HPA is scaling on CPU/Memory, then the recommendations from the VPA (and Goldilocks) will be exactly the same as what your HPA is set to. So, if you have a memory request of 400m, and your HPA is set to 75% target CPU, then you'll get a recommendation for 300m. If HPA is configured using CPU or Memory as the scaling target, you cannot effectively gather a good recommendation from Goldilocks.
VPA can run in different modes. The way we install it with Goldilocks is in recommender mode only, so it doesn’t make any changes. You can also install the VPA in updater mode. In that case, if your average CPU utilization hits the target you set it to, the VPA will delete your pods. That forces the pods to be recreated using the new requests that the VPA thinks you need, because pod specs are immutable. The only way to change the pod resource request is to delete and replace the pod with a new resource request with the new pod specs.
Typically, people don’t like to use VPA in updater mode because it can be quite disruptive. If (or when) the pod goes above or below the target you set, your pods will be deleted and recreated, which could result in a lot of throttling.
Let’s look at an example. If you have both HPA and VPA set to make changes if memory utilization gets to 90%, then the HPA will be scaling out the number of pods to reach the memory utilization of 90% or less. At the same time, VPA will try to delete your pods and create new ones with higher memory resource requests. If the VPA increases the amount of memory at the same time that HPA increases the number of pods, whichever one makes a change first results in a decrease in the average percentage of utilization. Then the VPA detects that the utilization is under the recommendation and it needs to change the pods. This can result in a cycle where each keeps making changes based on the adjustment the other made, rather than running smoothly.
Our recommendation is to have autoscaling on in various places, but don’t install the VPA chart by itself because by default it's on in updater mode. If you have both HPA and VPA adjusted on memory utilization and CPU, it will make your workloads do wonky things. To get more accurate recommendations and keep your pods running smoothly, install VPA with the updater turned off, and make sure you set your resource requests and limits based on this new understanding of how HPA and VPA work together (or don’t!).
If you have another question (or have an idea for how Goldilocks could be better!), we’d love to hear from you. The best way to reach us by asking a question in our Slack Community or through a Pull Request or Issue on Github. If you haven’t tried using Goldilocks to get your resources requests and limits “just right,” check out this post to learn more — including how to install it.

