
Estimating how much you are spending (or wasting) on a particular Kubernetes workload is hard. The good news is that there are some reasonable strategies for estimating how much a given workload costs.
In this post, we’ll discuss five major problems that affect cost estimation, and touch upon the strategies we use to overcome these problems in the Fairwinds Insights cost dashboard. We’ll present a more in-depth review of right sizing in a forthcoming blog.
Say we have a Node, which costs us $20/month. Say it has 5GB of memory and 5 CPUs we can put to use. (Note: this isn’t a very realistic node, but it makes the diagrams and math come out nice 🙂)

And here’s a workload, which needs 2 GB of memory, and 2 CPUs in order to run:

We can fit up to two Pods worth of this workload in a single node:

But if we want to add a third Pod for the workload, there’s not enough space left. So we’ll need to add (and pay for) a new node:
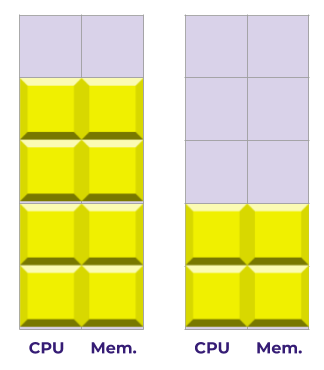
Note that there’s a little bit of wasted space on our first node - we’ve got 1GB of memory and 1CPU just sitting there. And our second node is very underutilized - less than half its resources are getting put to use.
This is the first and primary problem of cost estimation: Kubernetes can’t split up one pod across multiple nodes. So if a whole number of pods don’t fit inside a single node, you’re going to have a certain amount of capacity that’s going to waste.
Solution: One solution here is to “right-size” the nodes. If we used a node with 4GB of memory and 4CPUs, our workload would fit perfectly, and there’d be no capacity going to waste:

Let’s consider a different kind of workload: one that’s very CPU-intensive. It needs 3 CPUs to run, but only 1GB of memory.

Now we can only fit 1 Pod worth of this workload into a single Node (using our 4CPU/4GB example):
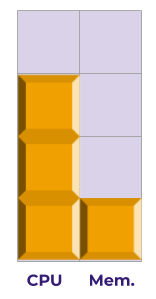
There’s a ton of unused capacity going to waste here - not only 1 CPU, but also 3 GB of memory. We’re only using half the Node, but if we want to spin up a second Pod, we’ll need a second Node, with the same amount of waste!
Solution: Again, we’ll want to right-size our nodes - cloud providers offer CPU-intensive and Memory-intensive nodes to handle exactly this problem.
Let’s say our smaller Node (4 CPUs and 4 GB) costs $16/mo. Using those numbers, we can come up with a rough estimate for how much each CPU and each GB of memory costs us. Say, of that $16, $8 goes to CPU, and $8 goes to memory. We can then infer that we’re paying $2 per CPU, and $2 per GB of memory.
So how much does our original workload cost us per pod?

Based on our math above, we’d say $2/CPU * 2CPUs + $2/GB * 2GBs = $8. Which makes sense - we can fit exactly two of these workloads on a $16 node. For reasons we’ll cover below, we call this the optimistic method of cost estimation.
But what about our second workload, the CPU-intensive one?
Let’s do the same math: $2/CPU * 3CPUs + $2/GB * 1GB = $8. So the optimistic method says this workload costs us $8. But as we saw above, we can only fit one of them per Node. So in reality, it’s costing us $16/mo, and the optimistic method doesn’t seem so accurate.
Is there another method of cost estimation that might give us a more reasonable answer? There is!
Instead of adding the CPU cost and the memory cost together, we can take the maximum of the two. This helps us account for memory-intensive or CPU-intensive workloads, that might cause extra capacity to go to waste. (Note that we’ll also need to multiply the result by 2, so we count the missing resource as well.)
So the math becomes MAX($2/CPU * 3CPUs, $2/GB * 1GB) * 2 = $12. This is a good deal closer to the $16 target. The remainder is attributable to the fully unused node capacity (i.e. the 1 CPU that is still going to waste, despite the fact that the Node carries a CPU-intensive workload).
We call this the conservative method of estimation. It prepares for a worst-case scenario in terms of Kubernetes’ ability to bin-pack workloads onto your Nodes.
For many workloads, the conservative method and the optimistic method will give similar estimates, but they diverge for CPU- or memory-intensive workloads. The basic difference is that the optimistic method assumes optimal bin-packing, while the conservative method assumes there will be some waste. Say, for instance, that we were also running a memory-intensive workload, one that needs only 1 CPU, but 3 GB of memory:

Kubernetes is smart enough to pack this together with our CPU-intensive workload, saving us the unused capacity:
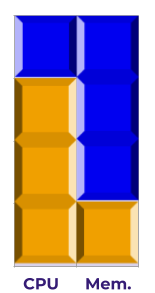
The conservative method would say that each of these workloads costs $12, for a total cost of $24. But Kubernetes has found a way to pack them into a $16 Node! We’ve overshot. That’s why it’s called conservative.
The optimistic method accounts for the clever bin packing, and would say that each of these workloads costs $8, for a total cost of $16, which is a perfect estimate, given that they fit exactly onto one $16 node.
Solution: So which one should you use? The answer is that it depends. If you’ve spent time optimizing your instance types, or if your nodes are much larger than your average workload, there’s a good chance that Kubernetes can find a way to pack workloads together in a cost-efficient way, and you can safely choose the optimistic method. Otherwise, we recommend the conservative method.

Another issue at hand is the fact that a Kubernetes workload doesn’t just use a fixed amount of CPU and memory. Resource usage can vary from second to second, and Pods may get killed or moved between nodes in response to these fluctuations.
To help with this issue, Kubernetes configuration gives engineers two fields for managing resources:
requests set the minimum resource usage of the workload. When a workload gets scheduled on a Node, you can be sure that at least this much is availablelimits set the maximum resource usage of the workload. When a Pod for the workload tries to use more than this amount, the Pod will get killed and a new one will start.The actual resource usage of a given workload will be somewhere between these two numbers, and will fluctuate heavily from second to second (just look at the Activity Monitor on your macbook to see how much this can vary!).
Solution: One way of estimating bottom-line workload cost is to look at that fluctuating number, and take an average over time. Another way of estimating workload cost is to look at requests and limits in order to provide a range of possibilities, or to take an average of the two.
Since Fairwinds Insights is primarily concerned with configuration validation, we opt for the second strategy - we want to tell you, given your current configuration, how much you can expect this workload to cost.
Kubernetes can only do its best with the information it's given. This is why it’s so important to specify requests and limits for every single one of your workloads.
For example, if one of your workloads duly requests 1GB of memory, but another workload on the same node hasn’t set requests or limits, the second workload could easily begin to gobble up all the resources available on that Node. This could prevent our original workload from getting all the memory it needs, hurting its performance.
Because it can be tricky to dial these settings in, some teams never set requests or limits at all, while others set them too high during initial testing and then never course correct. To appropriately estimate cost, we need to set the right limits and requests. Fairwinds Insights uses Goldilocks, a free open source tool, to analyze actual resource usage and recommend settings for requests and limits that are “just right”.
Understanding the financial costs of each of your organization’s applications impact is important, but when they’re all running together in Kubernetes, it can be quite difficult. Fortunately, there are some reasonable ways to solve each of the problems with Kubernetes cost estimation.
By using a combination of right-sizing (more to come on that), adopting the right methods (e.g. conservative vs. optimistic), and employing configuration validation tools like Fairwinds Insights and Goldilocks, you can ensure your Kubernetes deployments run efficiently.
Fairwinds Insights is available to use for free. You can sign up here.


